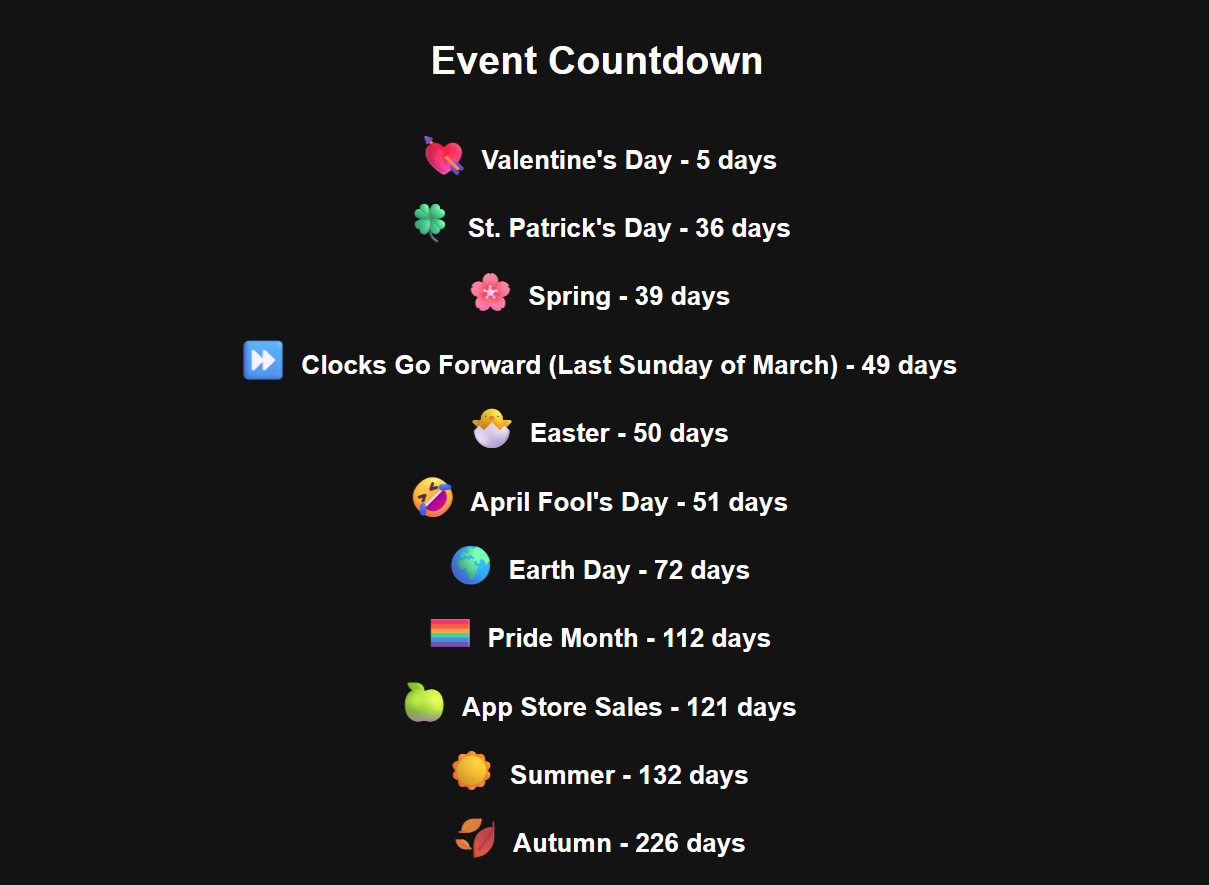
This is a simple web-based application that allows users to view a countdown to various events. The app dynamically calculates the days remaining to the next occurrence of a set of predefined events (e.g., New Year’s Day, Valentine’s Day, Christmas). The event countdown adjusts based on the current date and always shows the next upcoming event.
Features
Displays a list of events with a countdown to the next occurrence.
Updates the countdown automatically to show the number of days left.
If an event’s date has already passed for the current year, it adjusts to the next year’s event.
Responsive design that works on both desktop and mobile devices.
Events Included
The app includes the following events:
New Year’s Day 🎉
Bitcoin’s Birthday 🟠
Burns Night 🏴
Valentine’s Day 💘
St. Patrick’s Day 🍀
Spring 🌸
Clocks Go Forward (Last Sunday of March) ⏩
Easter 🐣
April Fool’s Day 🤣
Earth Day 🌍
Bonfire Night 🎆
Pride Month 🏳️🌈
Summer ☀️
App Store Sales 🍏
World Emoji Day 📅
Autumn 🍂
Clocks Go Backward (Last Sunday of October) ⏪
Halloween 🎃
Remembrance Day 🌍
Black Friday Sales 🫰
Thanksgiving (US) 🦃
Winter ❄️
Christmas 🎄
Technologies Used
HTML: For structure and content of the app.
CSS: For styling and responsive design.
JavaScript: For calculating the days remaining and dynamically updating the event list.
The app defines a list of events with specific dates (e.g., 2024-01-01 for New Year’s Day).
It calculates the number of days remaining until each event using JavaScript, adjusting for events that have already passed in the current year.
The events are displayed in a sorted order, with the nearest event at the top.
Each event is displayed with an emoji and the number of days left until the event occurs.
Days Calculation Logic
The app checks if the event date has passed for the current year. If it has, the app calculates the countdown for the same event in the following year.
The days remaining are calculated and displayed dynamically.
Customisation
To add or modify events, you can update the events array in the script section of the index.html file. The array contains objects with the following properties:
emoji: A string representing the emoji associated with the event.
name: The name of the event.
date: The date of the event in the format YYYY-MM-DD.
Sentiment Analysis is determining whether a written piece of text has a positive, neutral, or negative
connotation. These written pieces of text are usually the reviews that are left by customers once they use products,
brands, services, and so forth. These reviews give an insight into how appealing or off-putting a particular product,
brand, or service was to the customer. These insights are extremely useful because they are not only an indicator of
customer satisfaction but also companies can use them to drive business decisions.
Sentiment Analysis models are built leveraging a deep learning approach utilizing the customer reviews of Amazon products. Since Long Short Term Memory Network (LSTM) is very effective in dealing with long sequence
data and learning long-term dependencies, it is used for automatic sentiment classification of future product reviews.
Sentiment Analysis of Amazon Product Reviews using an imbalanced dataset
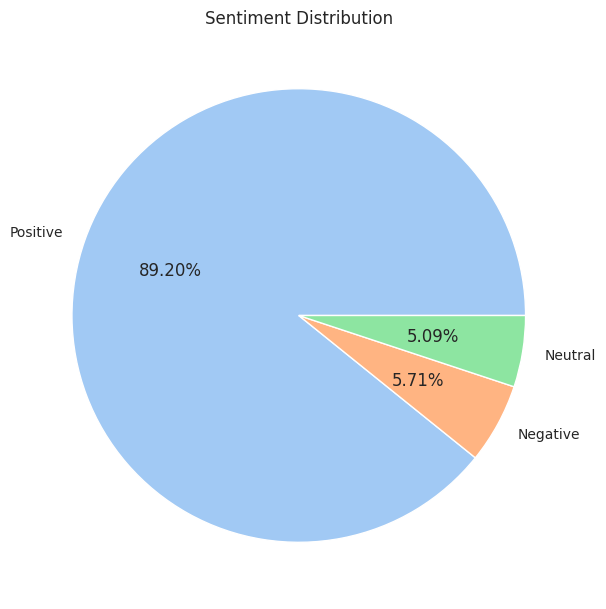
The initial sentiment model is trained and evaluated using the following sentiment distribution:
Positive Reviews: 89.02%
Neutral Reviews: 5.09%
Negative Reviews: 5.71%
Usage of pre-trained GloVe Word Embeddings
Explored different settings to build the sentiment model based on the following:
Batch Size
Number of LSTM Layers
Number of Units per LSTM Layer
Dropout Values
Absence or Presence of Dense Layer before the output layer
Epochs
Patience during Early Stopping
Word Stemming or Lemmatizing
Trained and Evaluated additional sentiment models by addressing the imbalance in data using the following methods:
Assigned class weights during the model training
Used SMOTE to synthetically create the oversampled data
Comparison between different sentiment models
Dataset
Consumer Reviews of Amazon Products is the dataset that will be used. It has a reasonable dimension i.e. it has over
34,000 consumer reviews for Amazon products like the Kindle, Fire TV Stick, and so forth. The dataset includes basic
product information such as name, review title, review text, review rating, and more for each product. The dataset is
publicly available on Kaggle.
In this dataset, the column reviews.rating has values ranging from 1 to 5. These values will be updated so that each of
them corresponds to a sentiment. Values 1 and 2 will be treated as a negative sentiment, value 3 will be treated as a
neutral sentiment, and values 4 and 5 will be treated as a positive sentiment. Additionally, the column reviews.text
holds the reviews.
Approach
Exploratory Dataset Analysis is done for the above-mentioned dataset. The text column is cleaned and the data
is then split into training, testing, and validation sets. Further, the data is tokenized and padded followed by preparing
the word embeddings that helps in setting up the embedding layer for the sentiment model. Evaluation Metric is finalized
and different settings are explored to build the sentiment model. Apart from the initial model that is trained and
evaluated using the imbalanced data, two other models are built. One of the models is trained using class weights and
the other model is trained using synthetically oversampled data. Finally, the results are compared for different models
trained and evaluated under the best setting.
Information About Files
dataset/1429_1.csv: Dataset of 34,660 consumer reviews for Amazon products
dataset/additional_dataset.txt: Provides links to additional dataset of 5,000 + 28,000 consumer reviews for Amazon
screenshot/people-sentiment.png: Screenshot of the people with negative, neutral, and positive facial expressions
screenshot/sentiment-distribution.png: Screenshot of the imbalanced dataset
screenshot/results.png: Screenshot of a few results
sentiment-analysis-lstm.ipynb: Google Colab notebook for the project
License
This project is licensed under the MIT License and for more details, see the LICENSE.md file
References
Here are some references I looked at while working on this project:
Papers
K. Baktha and B. K. Tripathy, “Investigation of recurrent neural networks in the field of sentiment analysis,” 2017
International Conference on Communication and Signal Processing (ICCSP), 2017, pp. 2047-2050,
doi:10.1109/ICCSP.2017.8286763.
T. Kati ́c and N. Mili ́cevi ́c, ”Comparing Senti- ment Analysis and Document Representation Meth- ods of Amazon Reviews,”
2018 IEEE 16th Inter- national Symposium on Intelligent Systems and In- formatics (SISY), 2018, pp. 000283-000286,
doi: 10.1109/SISY.2018.8524814.
J. C. Gope, T. Tabassum, M. M. Mabrur, K. Yu and M. Arifuzzaman, ”Sentiment Analysis of Ama- zon Product Reviews Using
Machine Learning and Deep Learning Models,” 2022 International Con- ference on Advancement in Electrical and Electronic
Engineering (ICAEEE), 2022, pp. 1-6, doi: 10.1109/ICAEEE54957.2022.9836420.
N. Sharm, T. Jain, S. S. Narayan and A. C. Kan- dakar, ”Sentiment Analysis of Amazon Smartphone Reviews Using Machine
Learning Deep Learning,” 2022 IEEE International Conference on Data Science and Information System (ICDSIS), 2022, pp.
1-4, doi: 10.1109/ICDSIS55133.2022.9915917.
Did you find this project useful? Which other setting do you think can be explored? In which other way can the imbalance
in this data be handled? Feel free to discuss your experiences on the discussion portal,
and I’ll be more than happy to discuss.
A simple 2-player game played as follows: An even number of coins is laid out in a row.
Taking turns, each player removes the coin on one of the ends of the row. The object is to have the
highest value in coins when all coins have been taken. Note that a greedy strategy of taking the largestvalue
end coin is not sufficient.
Consider this situation:
5, 25, 10, 1
In this case, the player should take the 1 on the right end; after the opponent takes either the 5 or the 10,
the player is guaranteed to get the 25. Simply taking the 5 “because it’s bigger” will result in the
biggest coin going to the other player.
Algorithm
If there are an even number of coins: Find the sum of all of the even-numbered coins, and all the odd-numbered coins. If the sum of the odd numbered coins is higher, take the leftmost coin; otherwise take the rightmost.
Minimize loss/maximize gain by evaluating every single possiblity of running the application after either taking the first or the last coin (Implementation choppy and doesn’t work well on large data sets).
Problem Definition.
Simply describe the “Traveling Santa Problem – Prime Paths” problem.
Methods
Provide detailed description on your methods, implementation details (pseudo code, flow chart, etc.),
Results
Analyze the results you get, for example, how do methods/strategies lead to a better solution? What do you learn from this project? Use figures, charts, and tables to assist your analysis. You can also compare your results with the Kaggle winners.
Conclusions
Provide your conclusions. Do you achieve your goal? Why or why not? If there a way to do it better?
Runs the app in the development mode.
Open http://localhost:3000 to view it in the browser.
The page will reload if you make edits.
You will also see any lint errors in the console.
npm test
Launches the test runner in the interactive watch mode.
See the section about running tests for more information.
npm run build
Builds the app for production to the build folder.
It correctly bundles React in production mode and optimizes the build for the best performance.
The build is minified and the filenames include the hashes.
Your app is ready to be deployed!
See the section about deployment for more information.
npm run eject
Note: this is a one-way operation. Once you eject, you can’t go back!
If you aren’t satisfied with the build tool and configuration choices, you can eject at any time. This command will remove the single build dependency from your project.
Instead, it will copy all the configuration files and the transitive dependencies (Webpack, Babel, ESLint, etc) right into your project so you have full control over them. All of the commands except eject will still work, but they will point to the copied scripts so you can tweak them. At this point you’re on your own.
You don’t have to ever use eject. The curated feature set is suitable for small and middle deployments, and you shouldn’t feel obligated to use this feature. However we understand that this tool wouldn’t be useful if you couldn’t customize it when you are ready for it.


 https://github.com/kay-who-codes/Calendar-Holiday-Countdown
https://github.com/kay-who-codes/Calendar-Holiday-Countdown